„More than a museum“
Beschäftigt man sich mit der Digitalität der Museen, so stößt man, vor allem im internationalen Kontext, immer wieder auf den Begriff „GitHub“. Dabei sind es meist außereuropäische Museen, die über GitHub nachhaltig eigene Datenbestände zur Verfügung stellen oder die, wie das Andy Warhol Museum Dokumente zur dynamischen Fortentwicklung auf offenen Servern ablegen (Bsp.: die „digitale Strategie“ des Andy Warhol Museum). Da mir im deutschen Umfeld immer wieder die Frage begegnet, was GitHub nun eigentlich ist, hier einige Erklärungen – und ein gerade in seiner Einfachheit überzeugendes Musterprojekt.
GitHub
Der webbasierte Filehosting-Dienst „GitHub“ wurde 2008 für Software-Entwicklungsprojekte gestartet und erscheint im Gebrauch durch die Museen eher als Fremdnutzung. Derzeit hat GitHub weltweit über zehn Millionen Nutzer und war 2011 bei Open-Source-Software-Projekten der populärste Dienst seiner Art. Zahlreiche bedeutende Open-Source-Projekte (wie etwa TYPO3 oder Joomla) setzen bei der Versionsverwaltung ihres Quelltextes auf den Filehosting-Dienst. Namensgebend ist das Versionsverwaltungssystem „Git„, mit dem kollaborative Projekte über lokale Repositorien gefahren werden können.
An einem Software-Projekt arbeiten heutzutage in der Regel viele Entwickler, die sich ggf. jeweils einem anderen Teil des Programms widmen. Um trotzdem einen möglichst transparenten Arbeits- (bzw. Entwicklungsprozess) zu gewährleisten und die einzelnen Arbeitsergebnisse wieder zusammenzuführen, nutzt man vielfach GitHub. Open-Source-Projekte können die Plattform kostenfrei benutzen. Wer sich vertiefend mit GitHub auseinandersetzen möchte, dem sei ein Artikel auf t3n angeraten, der die wichtigsten Funktionen und Begriffe kommentiert.
Wie sieht nun prototypisch ein Angebot aus, das die Museen auf GitHub entfalten? Zur Anschauung möchte ich auf das besonders simple Angebot des MoMA sehen:

Das MoMA auf GitHub
Das Angebot des MoMa ist seit Juli 2015 unter der URL https://github.com/MuseumofModernArt abrufbar. Unter der Bezeichnung „collection“ beinhaltet das Angebot gerade mal drei Files: eine CSV-Datei mit den eigentlichen Daten („Artworks.csv“), eine Readme-Datei mit beschreibenden Informationen und eine „License“ mit dem „Statement of Purpose“.
Das MoMA selbst beschreibt das Angebot als ein „research dataset“: die Offerte beinhaltet „basic metadata“ für 125.000 Objekte aus der eigenen Sammlung und dokumentiert diese in einer rustikalen Tabelle mit Kerndaten wie Titel, Künstler, Entstehungsdatum, Technik, Format, Ankaufdatum oder einer zugehörenden URL. Abbildungen zu den Objekten sind nicht enthalten. Einige Datensätze sind unvollständig und mit einer Anmerkung “not curator approved” gekennzeichnet. Die Daten liegen im einfachen CSV-Format vor und sind freundlicherweise nach UTF-8 kodiert. Lizenziert ist der Datensatz nach „public domain“ mit einer CC0-Lizenz. Updates an den Datensätzen lassen sich via GitHub einfach über die „releases“ und „commits“ nachvollziehen.
„Use our collection“
Die Sammlung des MoMA verzeichnet gut 200.000 Objekte aus den vergangenen 150 Jahren. Bei der Arbeit und Kommunikation folgt das Museum der Maxime: „MoMA is committed to helping everyone understand, enjoy, and use our collection“. Neben der Schausammlung und den temporären Ausstellungen werden dazu u.A. auf der eigenen Website gut 61.000 Kunstwerke von fast 10.000 Künstlern ausgeführt und über geeignete Erschließungsinstrumente, vor allem eine filterbare Suche, dokumentiert. Mit dem Angebot auf GitHub wird diese Informationsofferte ausgedehnt und insbesondere die Möglichkeiten des „Use“, des „Gebrauchs“, potenziert. Oliver Roeder hat jüngst über Ansätze der Auswertung der frei verfügbaren Daten publiziert und eine Handvoll spannender Grafikern erstellt.
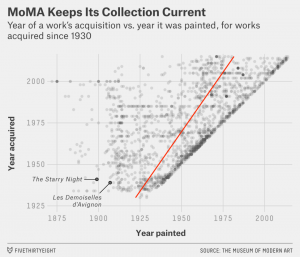 Der Zugriff auf die Daten ist simpel und die Lizenzierung erlauben nahezu jeglichen (sinnvollen) Einsatz. Projekte wie Hackathons (vgl. http://codingdavinci.de/) führen die Perspektiven der Nutzbarkeit solcher Daten schnell vor Augen. Die Tate gibt auf Ihrer seit 2013 verfügbaren GitHub-Seite sogar Informationen über entsprechende abgeschlossene Projekte (Examples“).
Der Zugriff auf die Daten ist simpel und die Lizenzierung erlauben nahezu jeglichen (sinnvollen) Einsatz. Projekte wie Hackathons (vgl. http://codingdavinci.de/) führen die Perspektiven der Nutzbarkeit solcher Daten schnell vor Augen. Die Tate gibt auf Ihrer seit 2013 verfügbaren GitHub-Seite sogar Informationen über entsprechende abgeschlossene Projekte (Examples“).
Im Vergleich mit den Angeboten anderer Museen auf GitHub (siehe z.B. Natural History Museum, London, UK, Indianapolis Museum of Art, Indianapolis, USA, Cooper Hewitt, Washington, USA oder Museum Victoria, Melbourne, Australia) wird schnell deutlich, wie rudimentär das Open Access Packet aus dem MoMA ist. Aber gerade in dieser Konstruktion könnte es für deutsche Museen ein Anfang sein. Tatsächlich ist mir bislang keine deutsche Kultureinrichtung bekannt, die entsprechend umfangreiche Datensätze via GitHub verfügbar macht. Hier lass ich mich aber gerne korrigieren, wenn Ihr da Hinweise geben könnt.